
大型語言模型(LLM),例如 OpenAI 的 GPT 系列和谷歌的 BERT已成為推動許多應(yīng)用的基礎(chǔ)技術(shù),從自動化客戶服務(wù)到高級研究工具。
訓(xùn)練這些模型需要大量的資金投入,主要是因為需要大量的參數(shù)空間和計算能力。訓(xùn)練 LLM 需要使用高端 GPU 或?qū)S?AI 硬件,這可能非常昂貴。
例如,單獨(dú)訓(xùn)練 GPT-3 的計算成本為估計范圍從約 50 萬美元到高達(dá) 460 萬美元不等,具體取決于培訓(xùn)過程中實現(xiàn)的具體硬件和運(yùn)營效率。
本文探討了將這些生成式 AI 模型付諸實踐所涉及的多方面費(fèi)用,主要關(guān)注基礎(chǔ)設(shè)施需求、數(shù)據(jù)管理以及云計算日益重要的作用。繼續(xù)閱讀,全面了解當(dāng)今影響大型語言模型開發(fā)的財務(wù)和后勤考慮因素。
什么是大型語言模型?
LLM 旨在模仿人類智能。它們接受大量數(shù)據(jù)集的訓(xùn)練,這些數(shù)據(jù)集包含來自書籍、網(wǎng)站和其他數(shù)字內(nèi)容的文本。
它們學(xué)習(xí)語言的統(tǒng)計特性,從而能夠根據(jù)收到的輸入生成連貫且與上下文相關(guān)的文本。例如,GPT 等模型經(jīng)過各種互聯(lián)網(wǎng)文本的訓(xùn)練,可以生成在許多上下文和主題中模仿人類寫作風(fēng)格的文本。

這些模型使用注意力和上下文感知等機(jī)制來處理相互關(guān)聯(lián)的文本部分。這使得模型能夠根據(jù)文本其他部分提供的上下文,以不同的方式衡量輸入文本不同部分的重要性。這種上下文感知對于理解和生成連貫且適合上下文的響應(yīng)至關(guān)重要。
BERT就是一個例子,因為它可以通過雙向閱讀文本(從左到右和從右到左)來理解句子中單詞的上下文,這比以前單向處理文本的模型有了很大的進(jìn)步。這種能力使得 BERT 特別適合那些需要深入理解語言上下文的任務(wù),例如回答問題或?qū)ξ谋具M(jìn)行分類。
大型語言模型的應(yīng)用范圍十分廣泛,涉及醫(yī)療保健等各個行業(yè),可以預(yù)測患者的結(jié)果基于歷史數(shù)據(jù),進(jìn)行娛樂,為虛擬角色生成逼真的對話。
現(xiàn)在,我們來討論一下使用云服務(wù)培訓(xùn)大型語言模型的成本。
使用云服務(wù)器訓(xùn)練大型語言模型的成本
由于多種原因,人工智能開發(fā)越來越多地轉(zhuǎn)向云平臺,包括GPU短缺,云服務(wù)是培訓(xùn) LLM 最簡單、最可靠的方式之一。它們的可擴(kuò)展性對于 AI 培訓(xùn)周期不斷變化的需求也非常出色。
NVIDIA 首席執(zhí)行官黃仁勛在NVIDIA GTC 2024例如,使用 25,000 塊基于 Ampere 的 GPU(很可能是 A100)訓(xùn)練 GPT-MoE-1.8T 模型需要 3 到 5 個月的時間。使用 Hopper(H100)進(jìn)行同樣的訓(xùn)練則需要大約 8,000 塊 GPU,耗時 90 天。
由于需要大量資金投入,大多數(shù)用戶不會從頭開始訓(xùn)練 LLM。相反,他們會利用其他公司或組織提供的預(yù)訓(xùn)練模型(如 ChatGPT 或 Llama2)。
使用此方法培訓(xùn) LLM 的方法有兩種:
托管您自己的模型。
按代幣付費(fèi)
讓我們看一下每種方法。
在云中托管模型
捷智算平臺提供全面的套件,支持整個機(jī)器學(xué)習(xí)生命周期——從數(shù)據(jù)存儲和計算到部署和管理。然而,基于云的培訓(xùn)的便利是有代價的。
在訓(xùn)練大型模型或具有數(shù)十億個參數(shù)的模型(如 GPT-3B 或 Falcon 180B)時,成本不僅僅在于 GPU(例如 A100)。在云服務(wù)環(huán)境中,您還需要考慮:
虛擬 CPU(vCPU)管理模型訓(xùn)練任務(wù)的執(zhí)行。
內(nèi)存(RAM)用于存儲計算的即時數(shù)據(jù)。
存儲成本,包括保存模型的參數(shù)和訓(xùn)練數(shù)據(jù)。
這些組件中的每一個都會增加成本,優(yōu)化資源使用以有效管理費(fèi)用至關(guān)重要。云提供商通常根據(jù)計算時間、分配的內(nèi)存量以及存儲或傳輸?shù)臄?shù)據(jù)量收費(fèi),這使得訓(xùn)練大型 AI 模型的成本特別高。
在捷智算平臺上訓(xùn)練大型語言模型的成本
讓我們分析一下在大型模型上訓(xùn)練 LLM 時如何實現(xiàn)這一點:
在撰寫本文時,A100在捷智算平臺上起價為每小時 1.67 美元或每月 1,219.94 美元。如果考慮其他成本(例如所需的 vCPU 和內(nèi)存),則每個費(fèi)用均根據(jù)位置收費(fèi)。
使用捷智算平臺上 A100 GPU 的中位數(shù)價格,以下是每種所需資源的成本:

建議使用多個 GPU 以獲得最佳效果。根據(jù)在 AWS 上訓(xùn)練相同模型的默認(rèn)實例,這是在捷智算上訓(xùn)練 Falcon 180B 所需的建議數(shù)量:
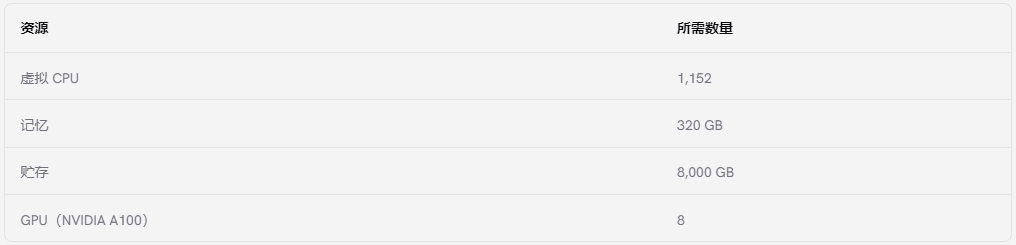
上述配置與 AWS 上用于在同一模型上訓(xùn)練 LLM 的默認(rèn)配置非常相似。要在捷智算上使用此配置,每月總計將超過 13,000 美元。以下是明細(xì):
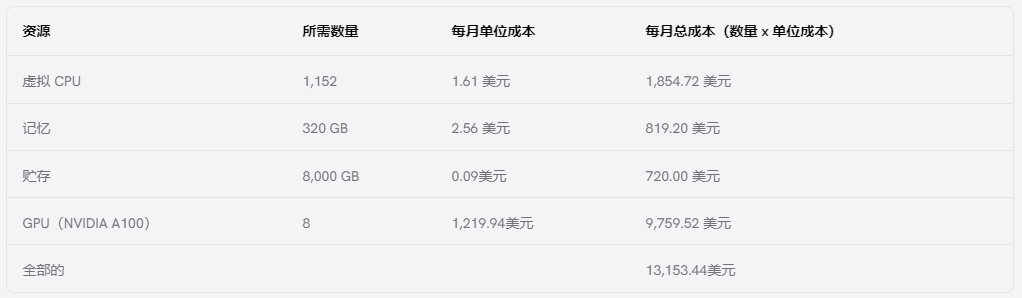
請記住,訓(xùn)練 LLM 可能需要數(shù)月時間,因此這筆費(fèi)用會隨著時間的推移而增加,特別是當(dāng)訓(xùn)練涉及對大量數(shù)據(jù)集進(jìn)行多次迭代時。CUDO Compute 定價極具競爭力,因此其他平臺上的計算成本通常更高。例如,在 AWS 上使用具有類似配置的實例(ml.p4de.24xlarge)每月將花費(fèi)超過 23,000 美元。
考慮到成本,一些用戶可能更愿意按代幣付費(fèi)。具體操作如下。
按照代幣(PPT)付費(fèi)獲取大型語言模型 (LLM) 訪問權(quán)限
培訓(xùn)和維護(hù) LLM 的高成本導(dǎo)致了按代幣付費(fèi) (PPT) 模式的興起,用于訪問這些強(qiáng)大的語言模型。其工作原理如下:
OpenAI 和 Google AI 等公司利用通過 API 公開的大量數(shù)據(jù)集對大量 LLM 進(jìn)行預(yù)訓(xùn)練。這樣一來,開發(fā)者和企業(yè)就可以使用這些模型(例如 GPT-3 或類似模型),而無需承擔(dān)訓(xùn)練此類模型的高昂成本和技術(shù)挑戰(zhàn)。
用戶無需承擔(dān)培訓(xùn)和基礎(chǔ)設(shè)施的前期成本。相反,他們只需根據(jù) LLM 在完成文本生成、翻譯或代碼編寫等任務(wù)時處理的標(biāo)記數(shù)量(大致相當(dāng)于單詞或子單詞)支付費(fèi)用。
對于不需要大量使用 LLM 的任務(wù),PPT 模式比內(nèi)部培訓(xùn)更具成本效益。用戶只需為實際使用的資源付費(fèi)。
按代幣付費(fèi)的好處:
降低成本:該模型消除了對硬件、軟件和訓(xùn)練數(shù)據(jù)的前期投資。
可擴(kuò)展性:用戶可以根據(jù)需要輕松地擴(kuò)大或縮小 LLM 的使用量,只需為他們消耗的代幣付費(fèi)。
可訪問性: PPT 允許更廣泛的用戶和小型公司訪問 LLM,而無需承擔(dān)高昂的內(nèi)部培訓(xùn)費(fèi)用。
為何培養(yǎng)大型語言模型 (LLM) 這么貴?
訓(xùn)練大型語言模型 (LLM) 需要巨大的計算能力。這些模型有數(shù)十億個參數(shù),訓(xùn)練它們需要在強(qiáng)大的硬件(如 GPU)上運(yùn)行數(shù)天甚至數(shù)月的復(fù)雜算法。提供這種基礎(chǔ)設(shè)施的云服務(wù)成本高昂,計算時間、存儲空間和數(shù)據(jù)傳輸?shù)纫蛩囟紩黾涌傮w費(fèi)用。
按代幣付費(fèi)的注意事項:
定價模式:不同的提供商根據(jù)特定的 LLM 模型和使用的令牌量提供不同的定價結(jié)構(gòu)。有些提供商可能會為更高的使用層級提供折扣。
控制有限:與內(nèi)部訓(xùn)練相比,用戶對預(yù)訓(xùn)練模型所使用的訓(xùn)練數(shù)據(jù)和具體配置的控制較少。
延遲:根據(jù)響應(yīng)的長度以及模型在后端硬件上每秒可以生成的令牌數(shù),用戶在通過 API 與 LLM 交互時可能會遇到一些延遲。
對于大多數(shù)希望使用 LLM 而又不想承擔(dān)內(nèi)部培訓(xùn)的巨大財務(wù)負(fù)擔(dān)的用戶來說,按代幣付費(fèi)模式是一種極具吸引力的替代方案。然而,在選擇此方法之前,了解定價結(jié)構(gòu)、控制限制和潛在的延遲問題非常重要。
控制大型語言模型培訓(xùn)成本的步驟
雖然大型語言模型的成本仍然很高,但有一些策略可以優(yōu)化資源利用率并降低費(fèi)用:
1.實施模型優(yōu)化技術(shù):
模型架構(gòu)選擇:仔細(xì)選擇模型架構(gòu),以平衡復(fù)雜性和所需性能。較小的模型通常需要較少的資源來訓(xùn)練。修剪技術(shù)可以進(jìn)一步減小模型大小,而不會造成明顯的準(zhǔn)確度損失。
訓(xùn)練數(shù)據(jù)優(yōu)化:確保您的訓(xùn)練數(shù)據(jù)質(zhì)量高且與當(dāng)前任務(wù)相關(guān)。過濾掉不相關(guān)的數(shù)據(jù)可以縮短訓(xùn)練時間并降低計算成本。
知識提煉:知識提煉在這個過程中,訓(xùn)練一個較小的“學(xué)生”模型來復(fù)制較大的“老師”模型的性能。這使得學(xué)生模型能夠從老師的知識中受益,而無需從頭開始訓(xùn)練較大的模型所需的大量計算資源。由于更緊湊,學(xué)生模型的部署效率更高,尤其是在資源受限的環(huán)境中。
混合精度訓(xùn)練: 混合精度訓(xùn)練在單個訓(xùn)練工作流程中使用半精度 (FP16) 和單精度 (FP32) 浮點格式。目標(biāo)是加快訓(xùn)練速度并減少內(nèi)存使用量,同時保持模型的準(zhǔn)確性和穩(wěn)定性。使用損失縮放等特殊技術(shù)來管理降低的數(shù)值精度對訓(xùn)練動態(tài)的影響。這可以在兼容硬件(如 NVIDIA H100 GPU)上完成。
2.考慮硬件優(yōu)化:
高效的硬件利用率:監(jiān)控訓(xùn)練期間的資源利用率。梯度累積等技術(shù)可以幫助實現(xiàn)更高的 GPU 利用率,從而縮短訓(xùn)練時間并降低成本。
選擇合適的硬件:選擇能夠滿足您特定訓(xùn)練需求且性價比最高的硬件。考慮使用較新的 GPU,例如 H100,其性能比前幾代產(chǎn)品有顯著提升。
云服務(wù)優(yōu)化:探索不同的云服務(wù)提供商和定價模式。與預(yù)留實例相比,按需定價可能會節(jié)省成本,具體取決于您的訓(xùn)練計劃可預(yù)測性。
我可以自己培養(yǎng)大型語言模型嗎?
從技術(shù)上講,您可以訓(xùn)練自己的大型語言模型 (LLM),但成本可能非常高。訓(xùn)練需要大量計算資源(強(qiáng)大的 GPU)和大量數(shù)據(jù)。云服務(wù)提供了這種基礎(chǔ)設(shè)施,但成本可能高達(dá)數(shù)百萬美元,具體取決于模型大小和訓(xùn)練時間。
3.優(yōu)化訓(xùn)練配置:
超參數(shù)調(diào)整:嘗試不同的學(xué)習(xí)率、批量大小和其他訓(xùn)練超參數(shù),以找到平衡訓(xùn)練速度和準(zhǔn)確性的最佳配置。
提前停止:實施技術(shù)來監(jiān)控訓(xùn)練進(jìn)度,并在達(dá)到所需的性能水平后停止訓(xùn)練。這可以避免不必要的資源消耗。
梯度檢查點:在訓(xùn)練期間定期保存模型狀態(tài)。這樣,您可以在發(fā)生硬件故障或中斷時從檢查點恢復(fù)訓(xùn)練,從而節(jié)省時間和資源。
4.考慮使用混合專家模型:
專用子網(wǎng):專家匯聚(MoE)架構(gòu)將訓(xùn)練工作量分配給多個專門的子網(wǎng)絡(luò)或“專家”。每個專家專注于數(shù)據(jù)的一個特定子集,與傳統(tǒng)模型相比,這有可能縮短訓(xùn)練時間并提高效率。技術(shù)集。
減少計算負(fù)荷:通過將訓(xùn)練分配給多位專家,MoE 可以更有效地利用硬件資源,減少總體計算需求并降低成本。
復(fù)雜性和研究: MoE 正迅速成為一種流行的方法,既能保持模型大小易于管理,又能涵蓋廣泛的主題。實施 MoE 需要仔細(xì)的配置和專業(yè)知識。
5. 協(xié)作并利用開源工具:
利用開源工具:利用 TensorFlow 或 PyTorch 等提供高效 LLM 訓(xùn)練功能的開源框架。
與研究機(jī)構(gòu)合作:與可能獲得 LLM 培訓(xùn)補(bǔ)貼計算資源的研究機(jī)構(gòu)合作。
數(shù)據(jù)采集也可以增加 LLM 的培訓(xùn),讓我們看看數(shù)據(jù)要求及其相關(guān)成本。
數(shù)據(jù)要求和成本
數(shù)據(jù)是 LLM 的命脈。數(shù)據(jù)質(zhì)量、數(shù)量和多樣性直接影響模型的有效性和準(zhǔn)確性。收集、清理和管理這些數(shù)據(jù)需要大量成本。數(shù)據(jù)需要足夠龐大和多樣化,才能訓(xùn)練出一個沒有偏見、可以在不同環(huán)境中推廣的模型。數(shù)據(jù)集創(chuàng)建過程涉及大量勞動力,包括人工任務(wù),例如監(jiān)督學(xué)習(xí)場景的標(biāo)記,這增加了成本。
然而,這些數(shù)據(jù)并非免費(fèi)提供,有效管理這些數(shù)據(jù)會大大增加總體成本。以下是法學(xué)碩士數(shù)據(jù)管理的主要財務(wù)方面的細(xì)目:
數(shù)據(jù)獲取:獲取 LLM 培訓(xùn)數(shù)據(jù)的主要方式有兩種:購買現(xiàn)有數(shù)據(jù)集或授權(quán)訪問它們。知名研究機(jī)構(gòu)和私營公司通常會整理和出售專門用于訓(xùn)練 AI 模型的文本和代碼數(shù)據(jù)集。這些數(shù)據(jù)集可能非常昂貴,具體取決于其大小、領(lǐng)域特異性和質(zhì)量。
數(shù)據(jù)存儲:存儲海量數(shù)據(jù)集需要大量存儲容量。傳統(tǒng)的本地存儲解決方案維護(hù)和擴(kuò)展成本高昂。云存儲服務(wù)提供了更靈活且更具成本效益的替代方案,但持續(xù)的存儲費(fèi)用會隨著時間的推移而累積,尤其是對于 TB 或 PB 級的數(shù)據(jù)集。
數(shù)據(jù)預(yù)處理:原始數(shù)據(jù)很少以其原始形式用于 LLM 培訓(xùn)。它通常需要大量的清理、標(biāo)記和格式化。這種預(yù)處理可能涉及:
清理:刪除不相關(guān)的信息(如代碼注釋、HTML 標(biāo)簽或重復(fù)條目)可能是一項計算量很大的任務(wù),尤其是對于大型數(shù)據(jù)集而言。
標(biāo)記:根據(jù)訓(xùn)練目標(biāo),可能需要用特定類別或信息標(biāo)記數(shù)據(jù)。這可能是一個需要人力的勞動密集型過程,也可以使用專門的工具自動完成,但會產(chǎn)生軟件許可成本。
格式化:確保數(shù)據(jù)具有適合 LLM 培訓(xùn)的一致格式可能涉及額外的處理和潛在的定制軟件開發(fā)。
此外,負(fù)責(zé)任地處理此類數(shù)據(jù)以遵守隱私法和道德標(biāo)準(zhǔn)會帶來額外的復(fù)雜性和費(fèi)用。數(shù)據(jù)匿名化、安全存儲以及遵守法規(guī)可能會增加任何 AI 項目的管理成本。
優(yōu)化這些數(shù)據(jù)管理流程對于成本控制至關(guān)重要。數(shù)據(jù)選擇(僅使用相關(guān)子集)和遷移學(xué)習(xí)(利用預(yù)訓(xùn)練模型)等技術(shù)可以幫助減少對大量昂貴數(shù)據(jù)集的依賴。
通過實施這些策略,研究人員和開發(fā)人員可以顯著降低 LLM 培訓(xùn)成本。精心優(yōu)化模型、利用高效的硬件和云服務(wù)以及采用節(jié)省成本的培訓(xùn)配置對于管理 LLM 開發(fā)的財務(wù)負(fù)擔(dān)都至關(guān)重要。











